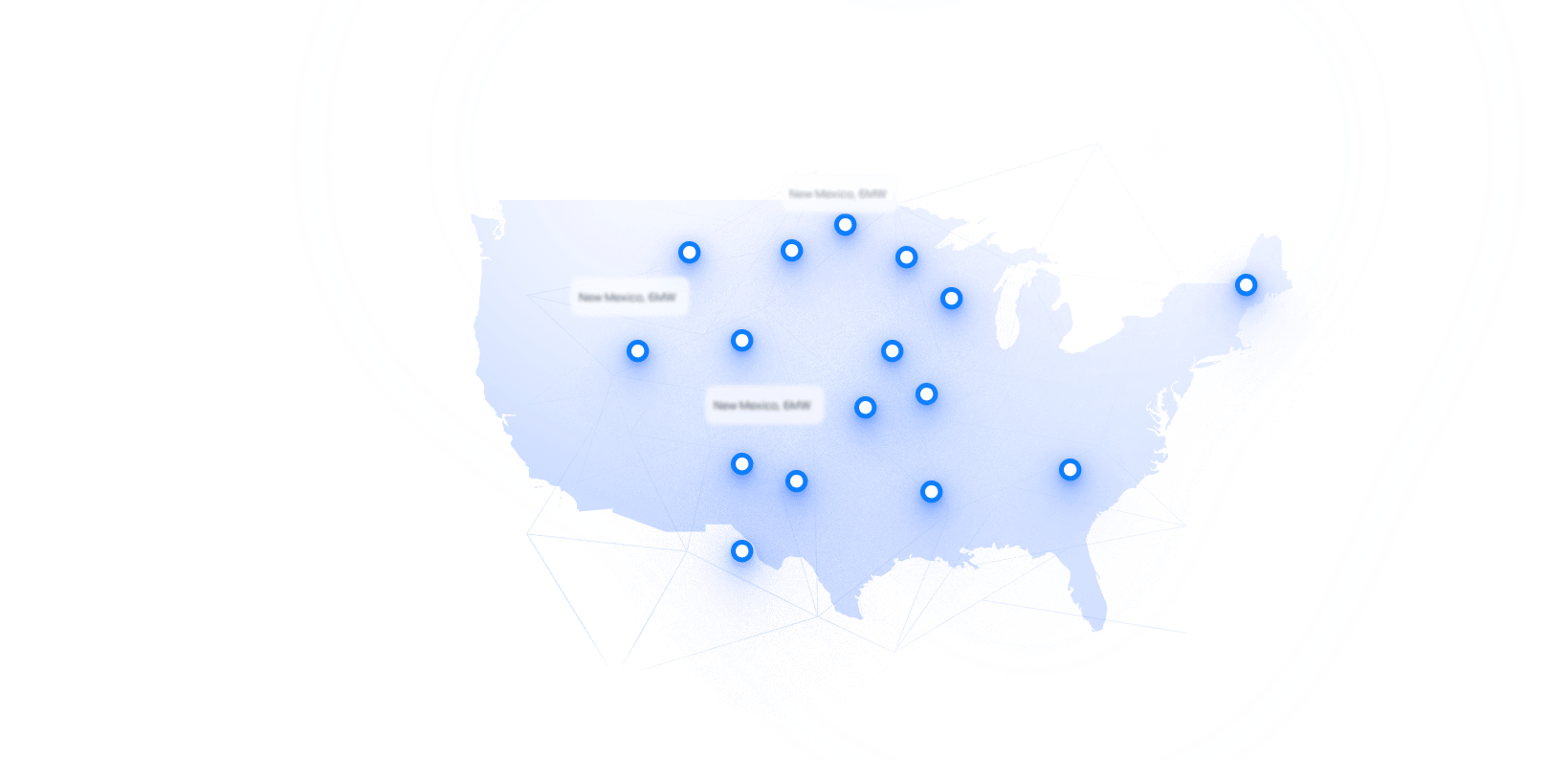
GPU & AI & HPC Colocation Pricing by Market (2026)
| Market | GPU Colocation (per kW) | Typical Rack Density | Notes |
| Northern Virginia (Ashburn) | $180–$300 / kW | 10–30 kW | Tight power availability, premium pricing |
| Dallas / Texas markets | $140–$240 / kW | 10–40 kW | Best balance of cost + availability |
| Chicago | $160–$260 / kW | 10–25 kW | Strong carrier-neutral ecosystem |
| Phoenix / Arizona | $130–$220 / kW | 15–40 kW | Popular for AI deployments |
| Los Angeles | $180–$320 / kW | 10–25 kW | Space constrained, high cross-connect costs |
| Pacific Northwest (OR/WA) | $120–$200 / kW | 15–50 kW | Strong for AI + power-heavy workloads |
| Washington State | $110–$180 / kW | 20–50 kW | Cheap hydro power, ideal for AI clusters |
| North Dakota / South Dakota | $100–$170 / kW | 20–60 kW | Lowest cost power, very limited competition |
| Atlanta | $140–$230 / kW | 10–25 kW | Growing secondary hub, good pricing |
| Denver | $140–$220 / kW | 10–30 kW | Central location, improving capacity |
| New Jersey (NYC metro) | $170–$280 / kW | 8–20 kW | Low latency to NYC, expensive power |
| Silicon Valley / Bay Area | $200–$350 / kW | 10–25 kW | Very limited capacity, highest pricing |
| Salt Lake City | $130–$210 / kW | 15–40 kW | Emerging AI-friendly market |
| Las Vegas | $130–$220 / kW | 15–40 kW | Tax advantages + proximity to CA |
| Columbus / Ohio | $130–$210 / kW | 10–30 kW | Cloud adjacency + lower costs |
| Minneapolis | $140–$220 / kW | 10–25 kW | Stable power, under-the-radar market |
| Montreal / Toronto | $120–$200 / kW | 10–30 kW | Lower power costs, strong for AI workloads |
*Notes: Actual quotes vary by date and your needs.
Real pricing depends on power, cooling, and availability – not rack space.
Price per kW → your real cost driver (not rack price)
Rack density → determines if your GPUs will even be accepted
Notes → where deals actually happen vs where you waste time




















